


Scale baby, scale
Про test-time compute scaling та принцип роботи "думаючих" моделей на кшталт o1

Заява Трампа з відкриття проекта Stargate по суті означала початок ексклюзивного фінансування OpenAI, запланованого на суму 500 млрд доларів за 4 роки. Ноам Браун, дослідник из OpenAI, писав: «подібні інвестиції можливі тільки тоді, коли наука ретельно перевірена і люди вірять, що вона буде успішною і трансофрмативною". В цьому пості й постараємось розібратись, які саме науково-емпіричні принципи стоять за цим.
А це доволі неочевидний момент, особливо для ще вчорашніх АІ скептиків. Ходило багато розмов, що моделі наступного покоління не дають очікуваних результатів, що масштабування моделей більше не працює, не вистачає даних і т.д. Але раптом все змінилось з появою моделі o1 і тою парадигмою, яку вона відкрила. Ми вже писали про методику Chain-of-Thought яка за ними стоїть, а зараз розглянемо важливий наслідок.
Ефективність моделей прогнозовано збільшується зі збільшенням test-time комп'юту, тобто кількості часу, яку виділяють моделі на вирішення завдання. На графіку нижче показана частота (точність) вирішення математичних задач олімпіадного рівня з бенчмарку AIME (вісь Оу) для моделі о1 при різних кількостях комп'юту (вісь Ох).

Зауважимо, що о1 була натренована з застосуванням Reinforcement learning (RL), але загалом цей принцип працює і для звичайних моделей (RL лише робить масштабування більш ефективним). Розберемо далі роботу від HuggingFace, яка показує, що маленькі моделі (стандартного LLM типу) Llama-3 на 1 і 3 мільярди параметрів перевершують свої старші моделі на 8 і 70 мільярдів відповідно, якщо дозволяти їм генерувати багато рішень за раз.
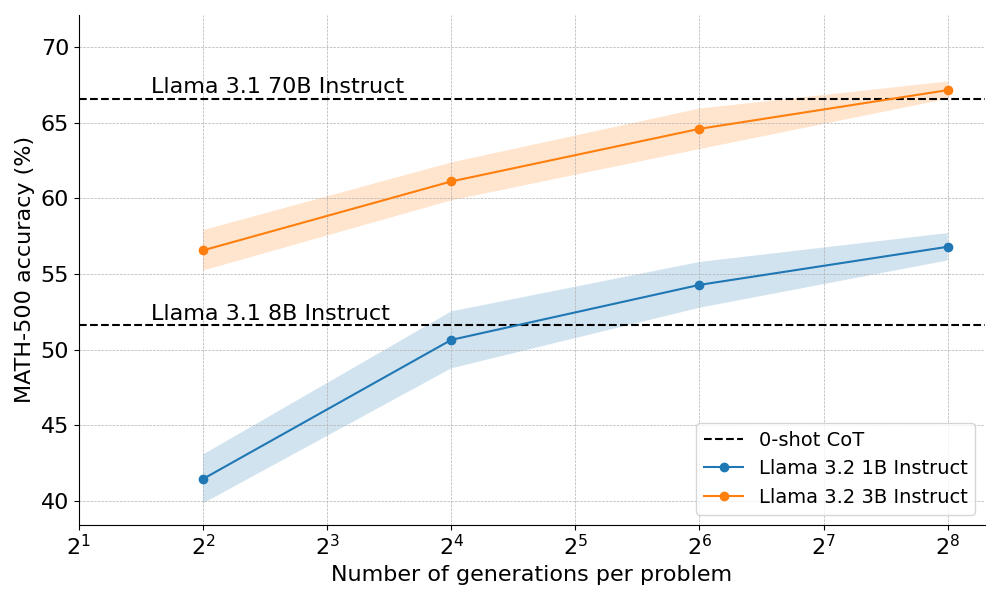
Як саме це працює?
Для початку, моделі вміють генерувати різні рішення "з коробки" - вихід від трансформера (архітектури майже всіх LLM) - це розподіл ймовірностей, з якого відбувається вибірка (семплінг). Ви даєте ту саму умову другий раз - дістаєте інший семпл, який приводить до іншого тексту відповіді, і часто до іншої відповіді по своїй суті (скажімо, як рішення математичної задачі). Найпростіший спосіб покращити якість відповіді тут через довший час її генерації - це давати ту саму умову N раз (кожен раз в новому діалозі), отримувати N відповідей від моделі і обирати ту, яка зустрілась найчастіше (техніка, відома як Majority Voting). Таким чином ми відсіюємо "аномальні" відповіді і вибираємо ту, до якої ведуть більшість ланцюгів рішень (всюди використовується Chain-of-Thought).
Така проста техніка на практиці швидко перестає "вигравати" від більшої кількості генерацій відповіді і виходить на плато. Тому придумали ряд інших, складніших методик, схематично зображених на картинці нижче.

Тут зображають дерево проміжних кроків рішення завдання, які модель генерує послідовно, використовуючи методику Chain-of-Thought. Починаючи від умови, закінчуючи фінальною відповіддю ці кроки з’єднані ребрами, якщо ідуть один за одним в межах одної відповіді LLM (а LLM генерують багато таких, як і в підході Majority Voting).
Ключова ідея, яка об’єднує всі ці методики, це використання так званого верифікатора (також відомого як Process reward model - PRM). Як правило це теж мовна модель, яку спеціально донавчають на оцінку проміжних кроків в ланцюгах Chain-of-Thought - тобто вузлів дерева з картинки вище. Грубо кажучи, таким моделям “згодовують” велику кількість ланцюгів Chain-of-Thought і вони вивчають, які кроки з цих ланцюгів статистично приводять до кращого результату. На виході отримуємо верифікатора, який присвоює чисельну оцінку кожному проміжному кроку в межах одного ланцюга Chain-of-Thought. Як використати ці оцінки?
Best-of-N: генеруємо N відповіді як і в Majority Voting, але вибираємо не найбільш поширену відповідь, а відповідь з найвищою оцінкою від верифікатора. 1 Це дозволяє уникнути систематичних помилок, від яких страждає Majority voting: навіть якщо модель схильна помилятись в якомусь завданні, достатньо одного відхилення де “моделі повезло” вибрати правильний спосіб розв’язку, як цей розв’язок буде відібраний як найкращий згідно з нашим верифікатором.
Beam search: а давайте оцінювати не лише фінальні відповіді, а й проміжні кроки також, і використовувати ці оцінки для продовження лише найбільш “обіцяючих” кроків (кроків з найбільшою оцінкою), а рішення з низькоціненими кроками обрубувати зразу. Це ніби дозволяє використовувати експертну інтуїцію того, які кроки статистично приносять кращий результат, що робить пошук більш напрямленим і ефективним порівняно з Best-of-N та Majority voting.
Diverse Verifier Tree Search (DVTS): те саме що і Beam search, але на етапі оцінювання наступних кроків дерево розбивається на незалежні піддерева. Це означає, що вибірка максимально-оцінених кроків буде відбуватись всередині піддерева (а не глобально, як в Beam search), тому будуть продовжуватись в тому числі кроки з нижчою оцінкою. Наприклад (див. на останню картинку), якщо в нас утворились піддерева з такими оцінками проміжних кроків: |0.9, 0.8|, |0.5, 0.79|, то у випадку Beam search відібрались би лише перші 2 кроки. А для DVTS, оскільки максимум береться в межах дерева, другим кроком відбереться 2 вузол з 2 піддерева з оцінкою 0.79. Це дозволяє досліджувати більший простір кроків (тобто відібрані кроки виходять більш різноманітні), що часто приносить виграш коли ми генеруємо дуже багато вузлів.
Результати порівняння ефективності цих алгоритмів від авторів HuggingFace можна подати таким чином:
Majority Voting < Best-of-N < Beam search;
Beam Search < DVTS коли кількість згенерованих рішень > 32, інакше Beam Search > DVTS
Чи якось так працює o1?
Було б добре знати! На інформаційній сторінці про цю модель від ClosedAI багато не вказано, але відповідь швидше за все негативна. Такий висновок можна зробити по чуткам (наприклад, що о1 - це єдина модель, що виключає використання верифікаторів як в згаданих вище підходах), або (що надійніше) - по випуску китайського аналога r1, який продемонстрував практично однакову ефективність з о1.
А для r1 в нас вже є стаття, де є практично всі деталі принципу роботи & тренування моделі. Серед найбільш важливих та цікавих деталей:
r1 не використовує жодної з розглянутих технік test-time скейлінгу2, натомість її здатність генерувати вдалі ланцюги думок досягається за рахунок reinforcement learning (RL) тренування
Конкретний алгоритм RL: Group Relative Policy Optimization (GRPO):
Вводиться Reward функція, яка застосовується на повних відповідях. Це дає змогу автоматично визначити правильність відповіді (через співставлення з еталонною відповіддю математичної задачі чи задачі по програмуванню). Крім доданку який відповідає за правильність, до Reward функції включають також доданки, відповідальні за формат відповіді: вони спонукають модель до генерації читабельних відповідей
Для поточної умови задачі (математики/програмування) за допомогою базової моделі (DeepSeek-V3-Base) генерується набір різних відповідей, кожна з яких оцінюється Reward функцією
Якщо модель присвоює високу ймовірність хорошим відповідям, ця поведінка закріплюється, якщо ж поганим - навпаки подавляється через оновлення параметрів базової моделі, які максимізують цільову функції GRPO (яка в свою чергу враховує оцінки від Reward функції).
Зверніть увагу, що ніде в алгоритмі GRPO ніде не вказано, як саме потрібно генерувати рішення, а лише те, наскільки бажаним є фінальним результат (через дизайн Reward функції). Проте, модель проходить, як кажуть автори само-еволюцію i вивчає ряд емерджетних поведінок:
Генерування Chain-of-Thought ланцюгів - ніхто не вказує вручну, що відповіді потрібно генерувати крок за кроком! Модель це вивчає самостійно, притому довжина ланцюгів стає все довшою і довшою в процесі тренування (вивчається простий принцип “думати довше - краще”)
Рефлексія: здатність повертатись до попередніх кроків та перевіряти їх. Забавно спостерігати, як модель раптом починає “думати вголос” так, як це роблять люди, вживаючи лексику яка здавалось би не обов’язкова для генерації правильної відповіді - так званий “Aha-moment”:

Перебір альтернативних підходів: в принципі очевидно, чому це підвищує точність, якщо модель не зразу доходить до рішення. Але цікаво, що перебирати різні підходи модель може навіть коли один з методів вже приніс їй якесь рішення - якщо додатково попробувати інші методи які дадуть те саме рішення, це значно збільшує ймовірність що відповідь правильна - і модель це розуміє.

Таким чином, модель яка тренується через Reinforcement learning ніби вчиться емулювати ось цю структуру дерева логічних кроків, яку ми бачили наприклад в підході Beam Search. Важлива різниця полягає в тому, що Beam Search - це алгоритм повністю складений людьми, де перебір альтернативних кроків чи оцінка вже зроблених кроків відбувається лише в наперед визначені моменти, притому в наперед визначеній кількості (напр. моделі дозволяється генерувати лише 4 продовження поточного рішення). У випадку ж з Reinforcement learning це дерево (яке складається з багатьох незалежних запусків моделей - forward pass-ів) сплющується в один forward pass, притому немає ніяких обмежень щодо його структури: кількості перебору варіантів, частота переоцінювання зроблених кроків і т.д. - все це підбирається самою моделлю залежно від того, що частіше приводить до правильних та читабельних відповідей.
А от o1 pro…
Ситуація може бути іншою з дорожчою версії моделі о1 - о1 pro (доступна лише за підпискою 200$/місяць). Відомий у вузьких кругах інсайдер Dylan Patel стверджує, що там якраз використовується відомий нам Best-of-N підхід, де модель генерує 5 відповідей і вибирає найкращий (вірогідно з використанням окремого верифікатора). Це узгоджується з тим, що писали працівники компанії: що o1 pro - це та сама модель о1, але поміщена в іншу систему (методику генерації відповіді). Це, зокрема, підвищує надійність відповіді3 - саме на цьому OpenAI робили акцент у своїй презентації.
Висновки
Test-time scaling - це нова універсальна парадигма масштабування моделей, де перфоманс прогнозовано збільшується з кількістю часу, яка виділяється на генерацію відповіді. Працює на будь-якій сучасній LLM без жодного попереднього тренування.
Reinforcement learning робить Test-time scaling більш ефективним: модель сама вчиться, яка структура відповіді буде найкраща для конкретної задачі, скільки часу їй думати і т.д., що робить підхід більш гнучким та ресурсо-ефективним. Так не треба підбирати параметри вручну (наприклад, кількість незалежних рішень, що генеруються) для кожної окремої задачі; якщо ж використовувати однакові параметри для всіх задач, то для простіших задач вони можуть бути надлишкові, для складніших ж - недостатні.
Різні алгоритми Test-time скейлінгу можна також застосовувати поверх моделей, натренованих через RL - це додатково підвищує надійність відповідей.
Використані джерела
Блогпост від HuggingFace: Scaling Test-time compute for open models.
Стаття від DeepSeek: DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Тарас Куцик.
Згідно з авторами, найкраще це робити після того, як однакові відповіді групуються разом і оцінюються вже групи, де оцінка групи - це кількість_елементів_групи * чисельна_оцінка_відповіді.
під час інференсу, тобто використання вже натренованої моделі. Під час ж самого тренування використовується Best-of-N семплінг, коли відбираються найкращі зі згенерованих моделлю відповідей, і на них проводиться додаткове навчання через звичайний Supervised Finetuning (SFT)
Працює той самий принцип з Majority voting, де аномальні відповіді відсіюються